Motivation
„Git ([ɡɪt], engl. Blödmann) ist eine freie Software zur verteilten Versionsverwaltung von Dateien, die ursprünglich für die Quellcode-Verwaltung des Linux-Kernels entwickelt wurde.“ (http://de.wikipedia.org/wiki/Git)
Jeder der Software entwickelt, stellt irgendwann fest, dass eine Versionsverwaltung sinnvoll ist. Ohne eine Anspruch auf Vollständigkeit zu erheben, gibt es meist folgende Gründe: alte Versionsstände zurückspielen, Branches (Zweige der Entwicklung) zu eröffnen, oder, um im Team zu arbeiten.
Neben Git gibt es noch andere, freie, VCS (Version Control Systems). Populär sind unter anderem CVS und Subversion. Wenn man die Szene betrachtet, fällt auf, dass der Trend immer mehr in Richtung Git geht.
Git bietet, wie auch CVS oder Subversion, Clients für alle möglichen Betriebssysteme herunterladen, u.a. Windows, Linux, Solaris, Mac OS X.
Arbeitsweise
Philosophie
Git ist dezentral (distributed) und unterscheidet sich von traditionellen, zentral verwalteten Programmen, wie etwa CVS oder Subversion, dadurch, dass kein zentraler Server benötigt wird. Ein Distributed VCS-System, wie Git, checkt im Gegensatz zu zentralen VCS-Systemen alle Dateien und Verwaltungsinformationen (Historie etc.) aus.
Vergleich mit CVS und Subversion
Ich habe mit einige Meinungen im Internet herausgepickt, die, teilweise subjektiv, für eine Verwendung von Git sprechen:
- Hat sich auch in großen Projekten bewährt (Linux-Kernel, Xorg, VLC, etc.)
- Trend spricht für Git: Anzahl der verfügbaren Git-Repositories steigt stark an
- Offline-Arbeiten immer möglich, da dezentral, d.h. es wird nach dem Erstellen der Arbeitskopie kein Zugriff mehr notwendig ist, alle Informationen sind in der Arbeitskopie
- Schneller als CVS oder Subversion, da man vorwiegend lokal arbeitet
- Mergen von Branches ist bei Subversion teilweise problematisch
- etc.
Die letzte aktuelle Git-Version (10.12.2012) lautet 1.8.0.2.
Git Workflow
Wenn man mit Git ein Verzeichnis unter Versionskontrolle stellen will, führt man folgende Schritte durch:
- Erstellen eines Verzeichnisses, das zum Beispiel dem Projektnamen entspricht.
- In das Verzeichnis wechseln und unter Git Versionskontrolle stellen (git init)
Damit hat man automatisch folgende Struktur geschaffen:

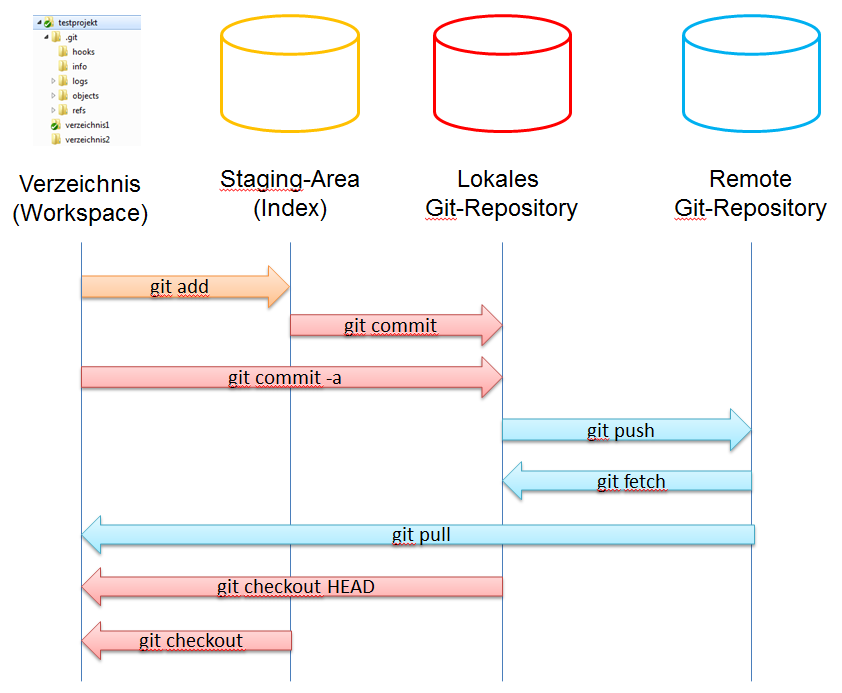
Ein Verzeichnis (Arbeitsbereich, Workspace), eine Staging-Area (Index) und ein lokales Git-Repository. Dateien aus dem Verzeichnis können in die Staging-Area verschoben werden (git add). Dateien aus der Staging-Area können in das lokale Git-Repository verschoben werden (git commit).
Alle Änderungen werden im Arbeitsbereich durchgeführt und haben zunächst keinen Einfluß auf die Git-Verwaltung, d.h. die Staging-Area und der Repository-Inhalt bleibt unverändert.
Die Reihenfolge ist also: Änderung(en) durchführen > git add > git commit
Wo ist der Server ?
Da Git dezentral arbeitet, ist ein Server nicht notwendig. Trotzdem kann man natürlich ein Git-Remote-Repository einrichten, also eine Instanz, die als Server fungiert und auf die ein lokales Git-Repository referenzieren kann.
Man kann von einem Server eine Kopie des Repositores in das lokale Git-Repository herunterladen (auschecken), dazu dient der Befehl „git pull“. Anschließend arbeitet man auf dem lokalen Git-Repository weiter. Will man die Änderungen auf den Server hochladen (einchecken), dann ist das mit dem Befehl „git push“ möglich.
Für den Fall, dass man ein Git-Remote-Repository einbindet, wird die Infrastruktur wie folgt erweitert:

Installation Git
Die grundsätzliche Installation von Git, egal, ob Server oder Client, wird im Folgenden für Linux- und Windows-Systeme beschrieben.
Linux
Auf Ubuntu oder Debian:
sudo apt-get install git-core python-setuptools
Windows
Git kann man direkt von http://git-scm.com/downloads herunterladen.
Applikationen
Linux
Unter Linux hat man das Terminal mit einer Shell (z.B. Bash) und kann git direkt aufrufen. Der Pfad auf git ist defaultmäßig bereits nach der Installation gesetzt.
Als Repository-Browser kann man „gitg“ verwenden.
Windows
Git-Bash
Nach der Installation erhält man die Git-Bash, eine Shell, von der aus alle Git-Befehle aufgerufen werden können.
Windows-Explorer
Zusätzlich werden im Windows-Explorer Kontext-Menus hinzugefügt.
Konfiguration Git
Der erste Schritt, bei der Verwendung von Git auf einem Rechner, sollte die Einrichtung des Users sein. Dieser erscheint in allen Änderungen und macht ihn identifizierbar (Rückfragen etc.).
Alle Befehle werden auf der Git-Bash ausgeführt!
Die Befehle dazu lauten:
<code>git config --global user.name </code>"Your Name"<code></code>
<code>git config --global user.email your@email.com<br /></code>
Siehe auch: http://git-scm.com/book/en/Customizing-Git-Git-Configuration
Lokal arbeiten
Auf Client-Seite, also lokal, arbeitet man mit einer Arbeitskopie. Ob diese Arbeitskopie lokal bleiben soll, durch Auschecken von einem Server heruntergeladen, oder später auf irgendeinen Server hochgeladen werden soll, ist erst einmal sekundär.
Projekte erstellen
Neuerstellung
Will man ein neues Projekt erstellen, dann verwendet man die Option „init“. Man erstellt ein Verzeichnis, wechselt dahin und gibt den Befehl „git init“ ein. Der Verzeichnisname entspricht damit dem Projektnamen
Beispiel:
mkdir testprojekt
cd testprojekt
git init
Vorhandenes Verzeichnis in ein Git-Repository umwandeln (lokal)
Wenn man bereits ein Projekt hat, kann man mit dem „init“ Befehl ein lokales Git-Repository erstellen. Es werden alle Dateien des entsprechenden Verzeichnisses direkt in das Repository übernommen.
Man wechselt in das entsprechende Projekt-Verzeichnis und ruft in der Git-Bash den Befehl „git init“ auf.
Repository von einem Server auschecken
Will man ein Projekt, etwa aus dem Internet lokal speichern und weiterbearbeiten, dann „klont“ man es 😉 Man erstellt damit eine lokale Arbeitskopie bzw. ein lokales Repository.
Änderungen durchführen
Workflow
Dateien hinzufügen
Man wechselt in das entsprechende Arbeitsverzeichnis und erstellt eine Datei, z.B. mit einem Texteditor.
Danach schiebt man diese Datei in die Staging-Area, mit dem Befehl:
git add
Will man mehrere Dateien gleichzeitig hinzufügen, kann man auch Joker „*“ verwenden, z.B.
git add *
Dateien, die im aktuellen Repository noch nicht im Index (Staging-Area) stehen, ermittelt man mit dem Befehl „git status“.
Dateien ändern
Sobald eine Datei unter Git verwaltet wird, wird sie „getracked“. Damit Änderungen im lokalen Git-Repository landen, müssen sie vorher in die Staging-Area verschoben werden. Das geschieht durch den Befehl „git add Datei“, auch wenn die Datei bereits in der Git-Versionsverwaltung existiert!
Der Befehl „git add“ macht Änderungen in einer Datei in der Staging-Area bekannt!
Der Befehl „git status“ zeigt u.a. den aktuellen Zustand der Staging-Area an, d.h. welche Dateien befinden sich darin und welche Dateien können comitted werden.
Dateien löschen
Mit dem Befehl „git rm“ kann man Dateien löschen:
git rm dummy.txt
Die Änderung ist dann automatisch in der Staging-Area und kann mit einem commit in das lokale Git-Repository verschoben werden.
Dateien umbenennen
Mit dem Befehl „git mv“ kann man Dateien löschen:
git mv alterName.txt neuerName.txt
Die Änderung ist dann automatisch in der Staging-Area und kann mit einem commit in das lokale Git-Repository verschoben werden.
Änderungen im lokalen Git-Repository bekanntmachen
Um Änderungen von der Staging-Area in das lokale Git-Repository zu übertragen, verwendet man den Befehl „git commit“.
git commit
git commit –m Kommentar
Änderungen rückgängig machen
|
Task |
Befehl |
Workspace |
Index |
Repository |
|
Datei anlegen |
touch Datei.txt |
Datei.txt V1 |
– |
– |
|
Datei in Staging-Area verschieben |
git add Datei.txt |
Datei.txt V1 |
Datei.txt V1 |
– |
|
Datei in Repository schieben |
git commit |
Datei.txt V1 |
Datei.txt V1 |
Datei.txt V1 |
|
Änderungen in Staging-Area rückgängig machen |
vi Datei.txt |
Datei.txt V2 |
Datei.txt V1 |
Datei.txt V1 |
|
git add Datei.txt |
Datei.txt V2 |
Datei.txt V2 |
Datei.txt V1 |
|
|
git reset |
Datei.txt V2 |
Datei.txt V1 |
Datei.txt V1 |
|
|
git checkout – Datei.txt |
Datei.txt V1 |
Datei.txt V1 |
Datei.txt V1 |
|
|
Änderungen im Workspace rückgängig machen |
touch Datei2.txt |
Datei.txt V2 |
Datei.txt V1 |
Datei.txt V1 |
|
clean –f |
Datei.txt V1 |
Datei.txt V1 |
Datei.txt V1 |
|
|
Workspace auf Stand der Staging-Area zurücksetzen |
vi Datei.txt |
Datei.txt V2 |
Datei.txt V1 |
Datei.txt V1 |
|
git checkout – Datei.txt |
Datei.txt V1 |
Datei.txt V1 |
Datei.txt V1 |
|
|
Workspace und Staging-Area auf aktuellen Stand des Repositories zurücksetzen |
vi Datei.txt |
Datei.txt V2 |
Datei.txt V1 |
Datei.txt V1 |
|
git add Datei.txt |
Datei.txt V2 |
Datei.txt V2 |
Datei.txt V1 |
|
|
git reset –hard |
Datei.txt V1 |
Datei.txt V1 |
Datei.txt V1 |
|
|
Workspace, Staging-Area und Repository auf vorigen Stand (seit dem letzten Commit) zurücksetzen |
vi Datei.txt |
Datei.txt V2 |
Datei.txt V1 |
Datei.txt V1 |
|
git commit –a |
Datei.txt V2 |
Datei.txt V2 |
Datei.txt V2 |
|
|
git reset –hard HEAD~1 |
Datei.txt V1 |
Datei.txt V1 |
Datei.txt V1 |
Änderungen anschauen:
- git status: zeigt Änderungen im Workspace und in der Staging-Area an, die durchzuführen sind.
- git log: zeigt die Commits im Repository an
- git diff: zeigt die Unterschiede zwischen Workspace und Index (Staging-Area)
- git diff HEAD: zeigt die Änderungen zwischen Workspace und Repository
Hochladen/Einchecken
Will man das lokale Git-Repository auf einen Server laden, führt man den Befehl „push“ aus. Beim erstenmal muss man mitteilen in welchen Branch auf dem „Hauptrepository“ die Arbeitskopie landen soll:
git push origin master
Versionierung/Tags
Mit dem Befehl „git tag -a“ kennzeichnet man einen Commit, also einen Stand im lokalen Git-Repository.
Beispiel:
git tag -a v1.0.0 -m „Creating the first official version.“
Will man sich vorher überzeugen, welche Dateien in den Tag aufgenommen werden, kann man den Befehl „git ls-files“ verwenden.
Um die vorhandenen Tags aufzulisten, kann man den Befehl „git tag“ verwenden. Danach kann man sich mit „git tag –v“ Details zu einem Tag anschauen:
git tag –v v1.0.0
Mit dem Befehl „git show“ kann man sich die Änderungen im lokalen Repository anschauen:
git show v1.0.0
Um einen bestimmten, getaggten Versionsstand in der Staging-Area und im Workspace auszuchecken, kann man „git checkout“ verwenden:
git checkout v1.0.0
Tags kann man auch löschen, hierzu dient der Befehl „git tag –d“
git tag –d v1.0.0
Für die Synchronisation mit einem remote Git-Repository dienen die Befehle
git push
git push –tags
git fetch
git fetch –tags
Entwicklungszweige/Branches
Ein Entwicklungszweig (Branch) ist eine Verzweigung in einem Projekt, die parallel zum bestehenden Hauptzweig erstellt wird. Hat man mehrere Entwicklungszweige zu pflegen, wie beispielsweise stable oder testing, kann man sich der Branches bedienen. Um bestehende Branches anzuzeigen, gibt man den Befehl „git branch“ ein.
Will man einen neuen Branch anlegen, verwendet man den Befehl „git branch“:
git branch Branchname
Beispiel:
git branch testing
Will man zu einem bestimmten Branch wechseln, verwendet man den Befehl „git checkout“:
git checkout Branchname
Beispiele:
git checkout testing
git checkout master
Um einen Branch zu löschen, verwendet man den Befehl
git branch –d Branchname
Um einen Branch auf ein bekanntes remote Git-Repository zu schieben, dient der Befehl:
git push origin Branchname
Beispiel:
git push origin testing
Um den Branch auf dem remote Git-Repository wieder zu löschen, dient der Befehl:
git push origin :Branchname
Beispiel:
git push origin :testing
Um sich nur Branches im lokalen Git-Repository anzuzeigen, verwendet man den Befehl:
git branch –a
Um sich nur Branches im remote Git-Repository anzuzeigen, verwendet man den Befehl:
git branch –r
Dateien im Workspace ignorieren
Die Datei „.gitignore“ gibt vor, welche Dateien von Git ignoriert werden sollen. Man kann diese Datei im Hauptverzeichnis des Workspaces anlegen, aber auch in den Unterverzeichnissen.
Beispiel einer Datei „.gitignore“:
# Can ignore specific files
.DS_Store
# Use wildcards as well
*~
*.swp
# Can also ignore all directories and files in a directory.
tmp/**/*
Man kann auch eine .gitignore Datei im HOME Verzeichnis anlegen. Sie betrifft dann alle Repositories, sofern sie durch folgenden (globalen) Git-Befehl aktiviert wird:
git config –global core.excludesfile ~/.gitignore
Server-Funktionalität einrichten
Wie bereits erwähnt handelt es sich bei Git um eine Peer-To-Peer-Lösung, ein Server ist also grundsätzlich nicht erforderlich. Aber was hält uns davon ab ein „Hauptrepository“ einzurichten, das zentral aller Versionsstände aller Projektes speichert?
Es gibt viele Möglichkeiten ein „Hauptrepository“ zu teilen, siehe auch: „8 ways to share your git repository“.
Der von mir präferierte Weg sieh wiefolgt aus…
Benutzer und Gruppen einrichten
Es ist sinnvoll auf dem Server eine Art-Git-Administrator einzurichten, z.B. den User „git“, der für alle zentralen Repository-Aufgaben zuständig ist. Zudem sollte man eine (oder mehrere) Gruppen einrichten, die Zugriff auf die Repositories erhalten, beispielsweise die Gruppe „developers“.
- Einrichten eines User „git“ und einer Gruppe „git“
sudo adduser git - Einrichten der Gruppe „developers“
sudo addgroup developers - Hinzufügen alle Accounts, die zur Gruppe „devlopers“ gehören sollen
vi /etc/group
Zentrales Repository einrichten
Ein zentrales Git-Repository auf einem Server, wird wie ein lokales Git-Repository eingerichtet. Für alle Aufgaben im zentralen Git-Repository verwenden wir den zuvor angelegten Benutzer „git“.
Man legt für diesen User ein Hauptverzeichnis „repo“ an unter dem alle Repositories als Unterverzeichnisse abgelegt werden.
Beispiel:
su – git
mkdir ~/repositories
cd repositories
Danach erstellt man für jedes Projekt ein leeres Unterverzeichnis und ordnet es der entsprechenden Gruppe zu.
mkdir testprojekt.git
sudo chgrp developers testprojekt.git
sudo chmod g+rws (Sticky-Bit nicht vergessen)
…
cd testprojekt.git
Hinweis: Es ist weit verbreitet, das zentrale Repositories mit dem Suffix „.git“ zu versehen, um sie als Git-Repositories kenntlich zu machen.
Danach initialisiert man das zentrale Repository mit dem Befehl „init“ und dem Schalter „bare“: Damit vermeidet man, dass eine Arbeitskopie erstellt wird und damit unnötige Git-Hilfsdateien erzeugt werden. Das zentrale Repository ist dann auch nicht dafür geeignet, direkt damit zu arbeiten. Man muss vorher das entsprechende Projekt auf einem Client auschecken, also ein lokales Git-Repository erzeugen. Zusätzlich wird noch der Schalter „—shared“ mitgegeben, damit können alle Gruppenmitglieder auf das Repository zugreifen.
sudo git init –bare –shared
Lokales Repository mit dem Hauptrepository auf dem Server verlinken
Ein lokales Repository kann nun zum zentralen Repository übertragen werden. Dazu wechselt man auf dem Client in das lokale Repository und setzt zunächst das origin:
cd testprojekt
git remote add origin ssh://:/~/repos/testprojekt.git
Lokales Repository zum Server hochladen (Einchecken)
Damit wird dem lokalen Repository mitgeteilt, auf welchem Server sich das „Original“ bzw. die zentrale „Quelle“, also das Hauptrepository befindet.
Danach schiebt man den Inhalt des lokalen Repositories auf den Server mit „push“:
git push origin master
Beim ersten mal muss der Hauptbranch „master“ mitgegeben werden.
Man kann auch von einem bestimmten Branch (Entwicklungszeig) im lokalen Repository auf einen bestimmten Branch im Hauptrepository „pushen“:
git push origin :
Beispiel: git push origin master:master
Hier kann auch ein komplett neuer Remote-Branch angelegt werden, indem master:neuerBranchName verwendet wird.
Hauptrepository (Server) auf Client auschecken
Um ein Hauptrepository auf einem Client auszuchecken, ist folgender Befehl notwendig:
git clone ssh://@/home/user/development/git/repo
Beispiel:
git clone ssh://juergen@aspire/~git/repositories/testprojekt.git
oder
git clone @:~git/repositories/
Beispiel:
git clone juergen@aspire:~git/repositories/testprojekt.git
Es wird dann auf dem Client ein Verzeichnis ohne den Suffix „.git“ angelegt
Anhang
Übersicht Workflow

Links
Git Homepage: http://git-scm.com
Ubuntu-Git Wiki:http://wiki.ubuntuusers.de/Git
http://www.jedi.be/blog/2009/05/06/8-ways-to-share-your-git-repository
Homepdate Git for Windows: http://msysgit.github.com
Michael’s Git Tutorial – Setting Up a Git Server: http://www.youtube.com/watch?v=SyMkLQLC3Kg
This post is not available in english! Sorry!
